
Deep Analysis — the analytics analogue to deep research
Design of the experimental “deep-analysis” feature for the Auto-Analyst


Deep research has quickly become a standout feature in search-powered language applications. Companies like Perplexity and OpenAI have both launched this feature, which enables users to create comprehensive research reports from a single query.
That same concept inspired the experimental deep analysis feature in our Auto-Analyst at FireBird Technologies. After trying out deep research, we found that there are three key processes that probably happen under the hood. This how we designed “Deep Analysis”
Ideate: Most users come in with a vague goal like “Why is churn rising?” but that single question can lead down many different paths. Maybe churn is tied to a recent product change. Maybe a competitor just launched something new. Or it could be part of a seasonal trend. A deep analysis has to explore all those possibilities and connect the dots. The ideation step is where the system branches out from the user’s original query to generate related and relevant sub-questions that need to be answered to fully answer the original goal.
Execute: Once we have a list of deep questions, the system needs to figure out how to tackle each one in a efficient manner. This part is all about creating a execution plan. Which agents should take which question? In what order should questions be handled? A well-structured execution plan helps the system avoid getting stuck and reduces chances of repeated answering the same question.
Synthesize: This is the final and most important step. All the answers generated during the execution phase need to come together in a deep analytical report. The report must be well-structured and provides data-driven insights to the user
Each of these steps — ideate, execute, and synthesize — requires its own carefully crafted components. In the next section of this post, I will break down how we designed and built each part.

Ideate
In AI applications, the quality of the response depends a lot on how the question is asked. If the user’s question is vague or unclear, the results usually won’t be very helpful. But we can’t expect every user to know exactly how to phrase things perfectly. That’s why, for deep analysis, it’s important for the system to ask smarter, more focused questions on its own.
At the same time, these follow-up questions need to be grounded in reality. They should be based on the data we actually have, so the system can actually answer them.
To handle this, the deep-questions LLM program works like this: it takes the user’s original goal, the available dataset, and then comes up with five (arbitrarily chosen number) related questions that dig deeper into the analytics query.
import dspy
class deep_questions(dspy.Signature):
"""
You are a data analysis assistant.
Your role is to take a user’s high-level analytical goal and generate a set of deep, targeted questions.
These questions should guide an analyst toward a more thorough understanding of the goal by encouraging exploration, segmentation, and causal reasoning.
Instructions:
- Generate up to 5 insightful, data-relevant questions.
- Use the dataset structure to tailor your questions (e.g., look at the available columns, data types, and what kind of information they can reveal).
- The questions should help the user decompose their analytic goal and explore it from multiple angles (e.g., time trends, customer segments, usage behavior, external factors, feedback).
- Each question should be specific enough to guide actionable analysis or investigation.
- Use a clear and concise style, but maintain depth.
Inputs:
- goal: The user’s analytical goal or main question they want to explore
- dataset_info: A description of the dataset the user is querying, including:
- What the dataset represents
- Key columns and their data types
Output:
- deep_questions: A list of up to 5 specific, data-driven questions that support the analytic goal
---
Example:
Analytical Goal:
Understand why churn has been rising
Dataset Info:
Customer Retention Dataset tracking subscription activity over time.
Columns:
- customer_id (string)
- join_date (date)
- churn_date (date, nullable)
- is_churned (boolean)
- plan_type (string: 'basic', 'premium', 'enterprise')
- region (string)
- last_login_date (date)
- avg_weekly_logins (float)
- support_tickets_last_30d (int)
- satisfaction_score (float, 0–10 scale)
Decomposed Questions:
1. How has the churn rate changed month-over-month, and during which periods was the increase most pronounced?
2. Are specific plan types or regions showing a higher churn rate relative to others?
3. What is the average satisfaction score and support ticket count among churned users compared to retained users?
4. Do churned users exhibit different login behavior (e.g., avg_weekly_logins) in the weeks leading up to their churn date?
5. What is the tenure distribution (time from join_date to churn_date) among churned customers, and are short-tenure users more likely to churn?
MAKE SURE THAT THE QUESTIONS ARE DISTINCT
"""
goal = dspy.InputField(desc="User analytical goal — what main insight or question they want answered")
dataset_info = dspy.InputField(desc="A description of the dataset: what it represents, and the main columns with data types")
deep_questions = dspy.OutputField(desc="A list of up to five questions that help deeply explore the analytical goal using the dataset")
query ="What is the best way to increase lifetime value?"
These questions would lead to a better understanding of the variable customer lifetime value, which we can then execute on.
FireBirdTech has served 13+ clients, from startups to big multi-national corporations, need help with AI?
We develop, consult and execute on AI.
Execute
The naive approach is to use the system as-is and send five separate queries into the multi-agent system. But that’s inefficient, with 4 agents and 5 queries could mean 20 API calls. At scale, this becomes slow and costly. A smarter planner is needed to group questions that the same agent can handle.
class deep_planner(dspy.Signature):
"""
You are an AI deep-planning system. Your task is to generate an optimized execution plan to answer a list of analytical questions using a set of specialized agents. Your main objective is to minimize the number of agent calls by:
- Avoiding redundant or unnecessary agent usage
Input:
- deep_questions: A list of analytical questions (q1, q2, q3, ...)
- agents_desc: A dictionary of agent names and their capabilities
Constraints:
- Each agent call can process up to 2 questions
- Preprocessing and data visualization tasks can be grouped if needed
- Agent outputs should be reused between questions when appropriate
- Minimize total agent calls
Output Format:
Each step maps one or more questions to an agent and optionally shows dependencies.
Use this format:
q1,q2: @agent_name [-> @dependent_agent_name]
Example Output:
{
"Step 1": "q1,q4:@preprocessing_agent",
"Step 2": "q1,q4:@statistical_analytics_agent -> @preprocessing_agent",
"Step 3": "q2,q3:@preprocessing_agent",
"Step 4": "q2,q3:@statistical_analytics_agent -> @preprocessing_agent",
"Step 5": "q5:@preprocessing_agent -> @statistical_analytics_agent",
"Step 6": "q1,q4:@data_viz_agent -> @statistical_analytics_agent",
"Step 7": "q2,q3:@data_viz_agent -> @statistical_analytics_agent",
"Step 8": "q5:@data_viz_agent -> @statistical_analytics_agent"
}
Notes:
- Group similar questions under the same agent
- Minimize duplicated work
- Use -> to indicate agent dependencies
- Only include necessary agent calls
Goal:
Generate the smallest and most efficient plan with the fewest agent calls and clear dependencies.
"""
deep_questions = dspy.InputField(desc="These are the deep questions created by the main goal")
agents_desc = dspy.InputField(desc="This is agents available and their descriptions")
deep_plan = dspy.OutputField(desc="This is the optimized plan")
deep_planner_agent = dspy.ChainOfThought(deep_planner)
plan = deep_planner_agent(deep_questions=questions, agents_desc=str(agents_desc))
print(plan.deep_plan)
The Auto-analyst sends @agent query to just that agent, which is just one API call. Each agent takes in text, outputs code & a summary

# You can use batch to concurrently send requests
responses = auto_analyst_sys.batch(queries, num_threads = 3,return_failed_examples=True,max_errors=100)The image above illustrates one step of the system, with a total of four steps in the process. These steps will be synthesized into a comprehensive analytics report. Similar to deep research, the system orchestrates multiple queries and synthesizes the results.
Looking for a reliable AI development partner? We develop solutions for enterprise, startups and academics
Synthesize
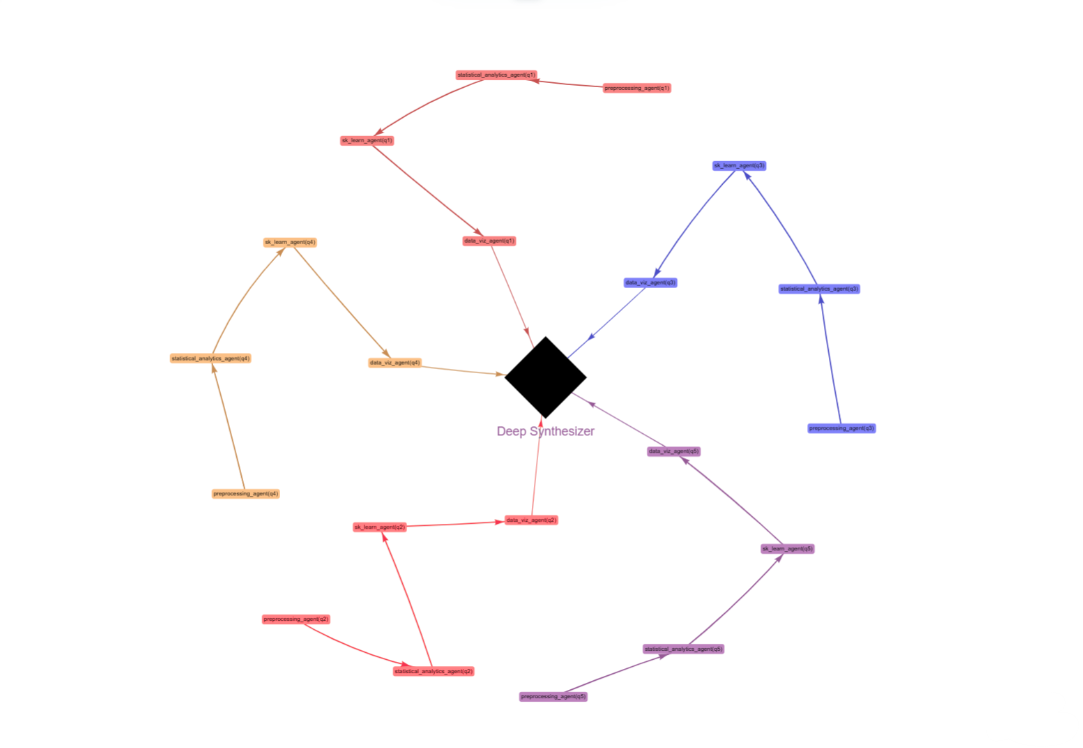
Each step on its own is separate and doesn’t form a clear story that answers the user’s original goal. The synthesizer’s job is to explain to the user what actions the system took and what insights they should get from it.

Each agent produces two things:
Code that works on the data
A summary of what was done
A good synthesis would include:
All the code from every agent
A step-by-step guide explaining what the system did
Actionable insights from each of the code outputs.
An conclusion to the user’s original query and recommendations!
The code from each step is already available, we need to synthesis the actions taken and results produced into actionable insights in the context of the query!
import dspy
class deep_synthesizer(dspy.Signature):
"""
You are a data analysis synthesis expert.
Your job is to take the outputs from a multi-agent data analytics system — including the original user query, the code summaries from each agent, and the actual printed results from running those code blocks — and synthesize them into a comprehensive, well-structured final report.
This report should:
- Explain what steps were taken and why (based on the query)
- Summarize the code logic used by each agent, without including raw code
- Highlight key findings and results from the code outputs
- Offer clear, actionable insights tied back to the user’s original question
- Be structured, readable, and suitable for decision-makers or analysts
Instructions:
- Begin with a brief restatement of the original query and what it aimed to solve
- Organize your report step-by-step or by analytical theme (e.g., segmentation, trend analysis, etc.)
- For each part, summarize what was analyzed, how (based on code summaries), and what the result was (based on printed output)
- End with a final set of synthesized conclusions and potential next steps or recommendations
Inputs:
- query: The user’s original analytical question or goal
- code_summaries: A list of natural language descriptions of what each agent’s code did
- print_outputs: A list of printed outputs (results) from running each agent's code
Output:
- synthesized_report: A structured and readable report that ties all parts together, grounded in the code logic and results
Example use:
You are not just summarizing outputs — you're telling a story that answers the user’s query using real data.
"""
query = dspy.InputField(desc="The original user query or analytical goal")
code_summary = dspy.InputField(desc="List of code summaries — each describing what a particular agent's code did")
print_outputs = dspy.InputField(desc="List of print outputs — the actual data insights generated by the code")
synthesized_report = dspy.OutputField(desc="The final, structured report that synthesizes all the information into clear insights")
synthesizer = dspy.ChainOfThought(deep_synthesizer)
Now each of the synthesized results, need to be used to create a final conclusion on the user’s query.
class final_conclusion(dspy.Signature):
"""
You are a high-level analytics reasoning engine.
Your task is to take multiple synthesized analytical results (each answering part of the original query) and produce a cohesive final conclusion that directly addresses the user’s original question.
This is not just a summary — it’s a judgment. Use evidence from the synthesized findings to:
- Answer the original question with clarity
- Highlight the most important insights
- Offer any causal reasoning or patterns discovered
- Suggest next steps or strategic recommendations where appropriate
Instructions:
- Focus on relevance to the original query
- Do not just repeat what the synthesized sections say — instead, infer, interpret, and connect dots
- Prioritize clarity and insight over detail
- End with a brief “Next Steps” section if applicable
Inputs:
- query: The original user question or goal
- synthesized_sections: A list of synthesized result sections from the deep_synthesizer step (each covering part of the analysis)
Output:
- final_summary: A cohesive final conclusion that addresses the query, draws insight, and offers high-level guidance
---
Example Output Structure:
**Conclusion**
Summarize the overall answer to the user’s question, using the most compelling evidence across the synthesized sections.
**Key Takeaways**
- Bullet 1
- Bullet 2
- Bullet 3
**Recommended Next Steps**
(Optional based on context)
"""
query = dspy.InputField(desc="The user's original query or analytical goal")
synthesized_sections = dspy.InputField(desc="List of synthesized outputs — each one corresponding to a sub-part of the analysis")
final_summary = dspy.OutputField(desc="A cohesive, conclusive answer that addresses the query and integrates key insights")Now lets compare how the system usually answers a simple query, verses the whole response generated by the ‘deep analysis’ system.

Now the deep analysis for the same query! The whole analysis is downloadable here!



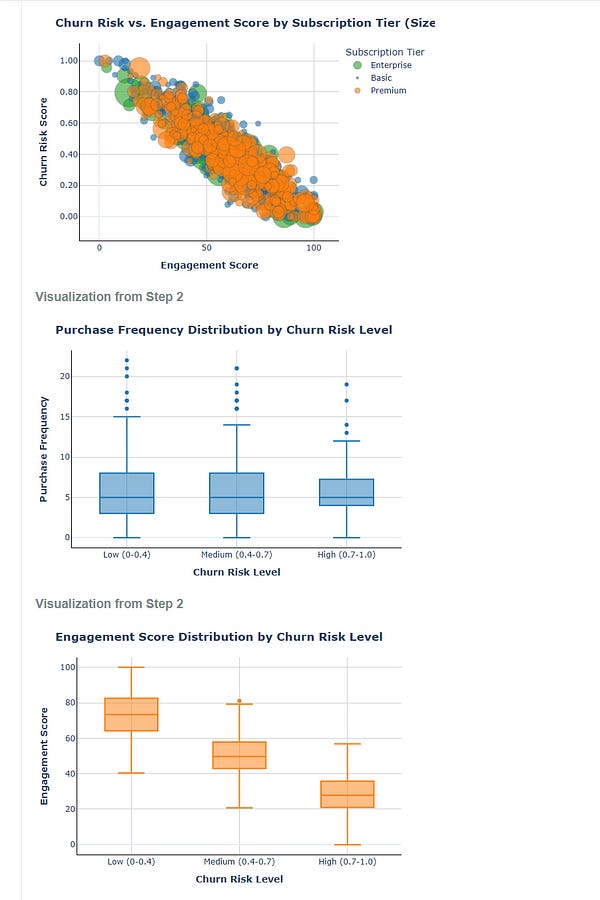


Conclusion
Deep Analysis — like many AI generated reports seems amazing when AI gets it right but that is always not the case. The report overall is great, and gives many insights to the user but it has these limitations
Repetition, despite the prompt explicitly saying that the queries should be distinct, the system often repeats the same analysis in different parts.
No outside Validation: For now, it relies solely on the dataset provided, it does not look at publicly available information for more context. It could also be provided company wide datasets to play with in a future iteration.
We intend to improve the system with more feedback! Stay tuned for updates. Follow FireBirdTech on Linkedin, Medium and Substack
Thank you for reading! The auto-analyst is available as a beta (as of April 24th 2025). Sign up for testing using the link below: